
If you have ever tried to pull together data from multiple sources, you know how tricky it can be to align them neatly. Different datasets, various identifiers, and incompatible formats can make merging a time-consuming process. DEMSCORE simplifies this by not only seamlessly harmonizing data from its partner Modules, but also enabling the smooth inclusion of external data, facilitating rich, cross-country analyses minimizing the usual hassle that comes with combining data from different sources.
While DEMSCORE v4 with 145 datasets and 25.000 variables is bigger than ever, we know that there are plenty of other datasets out there that we do not (yet) include. In this post, we will walk you through a little DEMSCORE-hack, illustrating how DEMSCORE can be of help even when using external datasets. We will use an example analysis of the relationship between corruption, organized violence and food insecurity for the countries Canada, Argentina, and Yemen.
Step 1: Selecting Data Sources
For this example, we will draw on two internal datasets, i.e., data that comes from DEMSCORE’s partner Modules, and one external dataset:
- Internal Data 1: Corruption Data from QoG, with the Bayesian Corruption Indicator as our variable.
- Internal Data 2: Fatality data from UCDP, using Cumulative Fatalities in Organized Violence as our indicator.
- External Data: Food Insecurity Data from FAOSTAT’s Suite of Food Security Indicators, specifically focusing on the Prevalence of Undernourishment.
DEMSCORE includes data on organized violence and corruption, and through the Quality of Government Environmental Indicators dataset, even numerous indicators from FAOSTAT. However, our indicators of interest, the FAOSTATs food security indicators, need to be integrated as external data.
Step 2: Choosing an Output Unit
To ensure compatibility across datasets, we choose QoG Country-Year as the Output Unit. This means that we will retrieve a dataset with one row per country and year, using the country identifiers and years available in QoG. This Output Unit is particularly useful because both QoG and FAOSTAT datasets rely on ISO country codes, allowing us to align country identifiers seamlessly. By selecting QoG Country-Year as our Output Unit, we can bring in data from UCDP’s indicators on fatalities, QoG’s indicators on corruption, and FAO’s indicators on food insecurity, into one dataset.
Step 3: Internal Data on Corruption and Fatalities
For our internal data, we select:
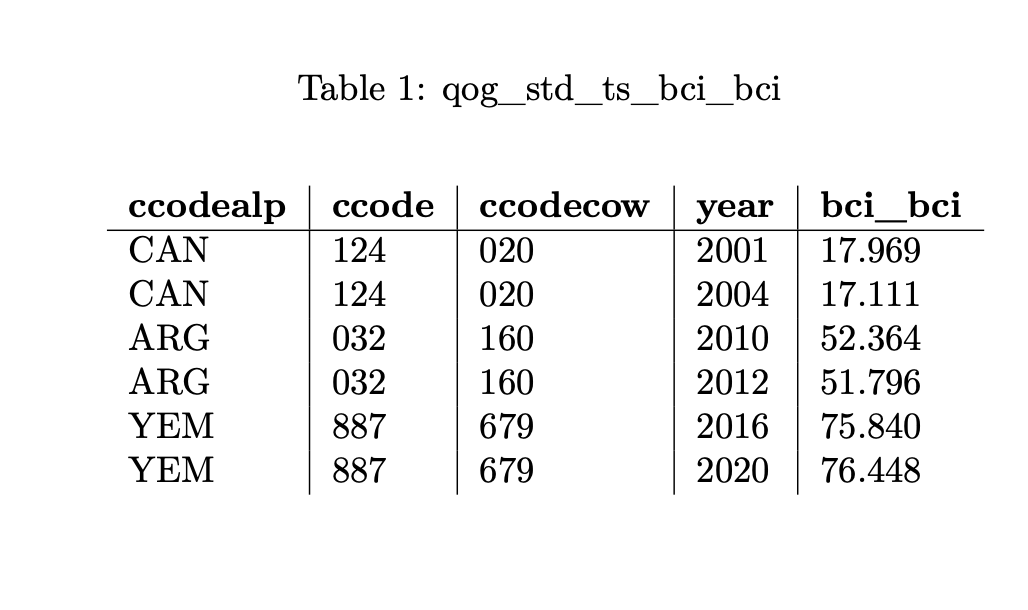
The Bayesian Corruption Indicator from QoG to measure corruption (Table 1), which uses ISO country codes (ccodealp and ccode) and COW country codes (ccodecow).
And Cumulative fatalities in Organized Violence from UCDP to measure fatalities (Table 2), using GW country codes (country_id)
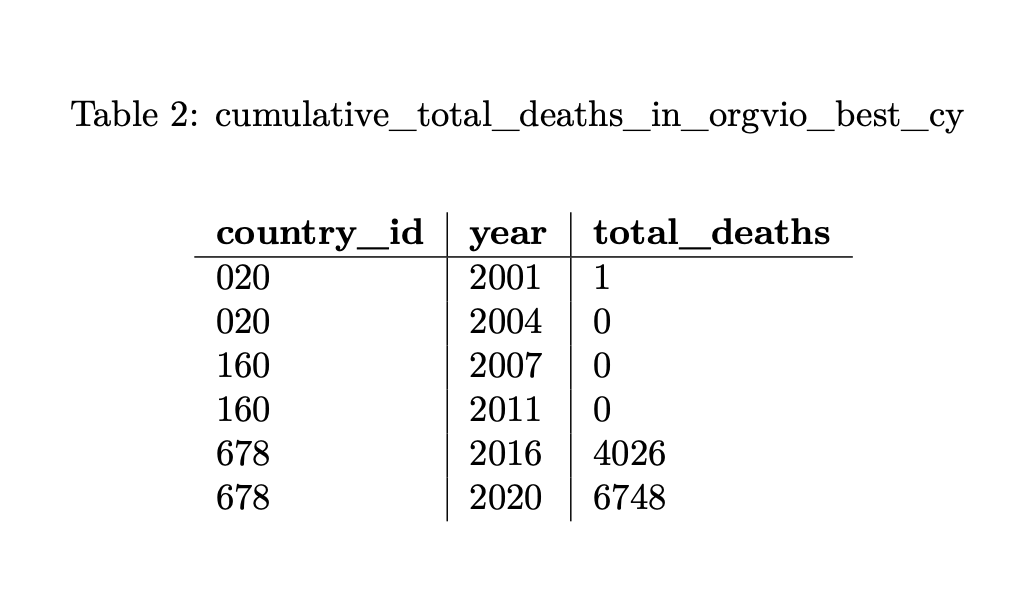
These two variables cannot be merged without adjustments, as becomes evident when looking at the country identifiers for Yemen. Even though QoG includes two different sets of identifiers, both available country codes for Yemen (ccodecow in Table 1 and country_id in Table 2) slightly deviate from the UCDP identifiers. Luckily, DEMSCORE already takes care of that and the two variables can be merged within seconds using the DEMSCORE download interface in a suitable Output Unit. If you want to learn more about the merging process and the underlying methodology, please refer to our methodology document.
Using QoG Country-Year as the Output Unit enables DEMSCORE to align both datasets by shared identifiers, ensuring compatibility.

The table above shows how DEMSCORE merges the two internal datasets: corruption from QoG (highlighted in blue) and organized violence from UCDP (highlighted in red). Different country codes often make it tricky to combine datasets, but DEMSCORE handles this automatically. By using the QoG Country-Year format, we ensure that the data lines up correctly without the need for manual adjustments. This example highlights how easy it is to bring together different data sources for a smoother analysis.
Step 4: Integrating FAO’s Indicator on Prevalence of Undernourishment
Now, let us integrate Table 4, an external dataset from FAOSTAT’s Suit of Food Security Indicators. We have chosen the variable Prevalence of Undernourishment to measure food insecurity and renamed it prev_und for simplicity.
FAOSTAT uses area_code as its unique identifier, also based on ISO codes. Because we are using QoG Country-Year as our Output Unit, we can directly match ccode in Table 1 with area_code in Table 4.

Step 5: Creating a Unified Dataset
After aligning the UCDP and QoG variables using DEMSCORE and retrieving the data with ISO country codes, we can do a very simple 1:1 merge between the FAO data and the customized DEMSCORE dataset, resulting in a unified dataset using ccodeapl, ccode, ccodecow, country_id, and year as the primary connectors. For the analysis, it is of course not necessary to keep all country identifiers, so for our final dataset, we only keep ccodealp. Without DEMSCORE, we would have needed to figure out the differences in country identifiers between QoG, FAO and UCDP ourselves. This final table brings together variables from all three datasets in just a few minutes, allowing for easy cross-country analysis of organized violence, corruption, and food insecurity:
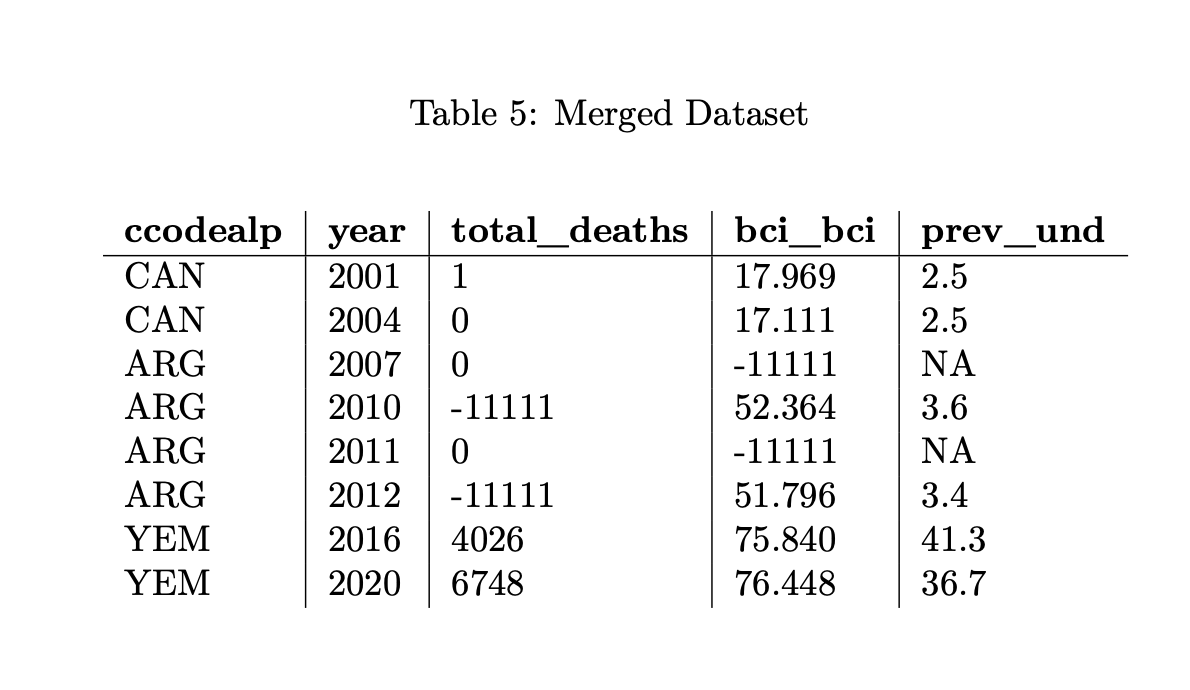
In this merged dataset:
- ccodecow and country_id is the initial connector between Table 1 and Table 2.
- area_code allows for the inclusion of external data from Table 4 through a direct merge to ccode. This enables the smooth matching of Table 4 and Table 2, despite the lack of common identifiers between those two
- year ensures temporal alignment, synchronizing observations across all three tables
- Any missing data for a specific Country-Year combination is marked as -11111
We hope that this post managed to illustrate how DEMSCORE can be used to harmonize external data sources with data available through DEMSCORE. The attentive reader might have also noticed that you can even go one step further: If you wish to match two datasets that are both not included in DEMSCORE and inconveniently use different country identifiers, let us say numeric ISO-3 codes and 3-letter Gleditsch-Ward identifiers, you can use DEMSCORE and create your own translation table by simply downloading an ISO-3 identifier variable and a 3-letter Gleditsch-Ward identifier variable, and use this table as a connecting element between your two external data sources.